
Chatting with Yourself
TLDR; I pointed a local LLM at my Obsidian vault and asked questions about my notes.
When I started my PhD, I transitioned my note-taking system from Evernote to Obsidian. Answering, “Why Obsidian?” is a completely separate post but in brief, it’s free and open-source, it uses Markdown (widely used text formatting engine—like HTML but much simpler), and the built-in features + community plugins are amazing. These features allow you to templatize common notes such as your daily note (see below), link between notes to easily see connections, and track sprawling TODO lists across ALL of your notes.
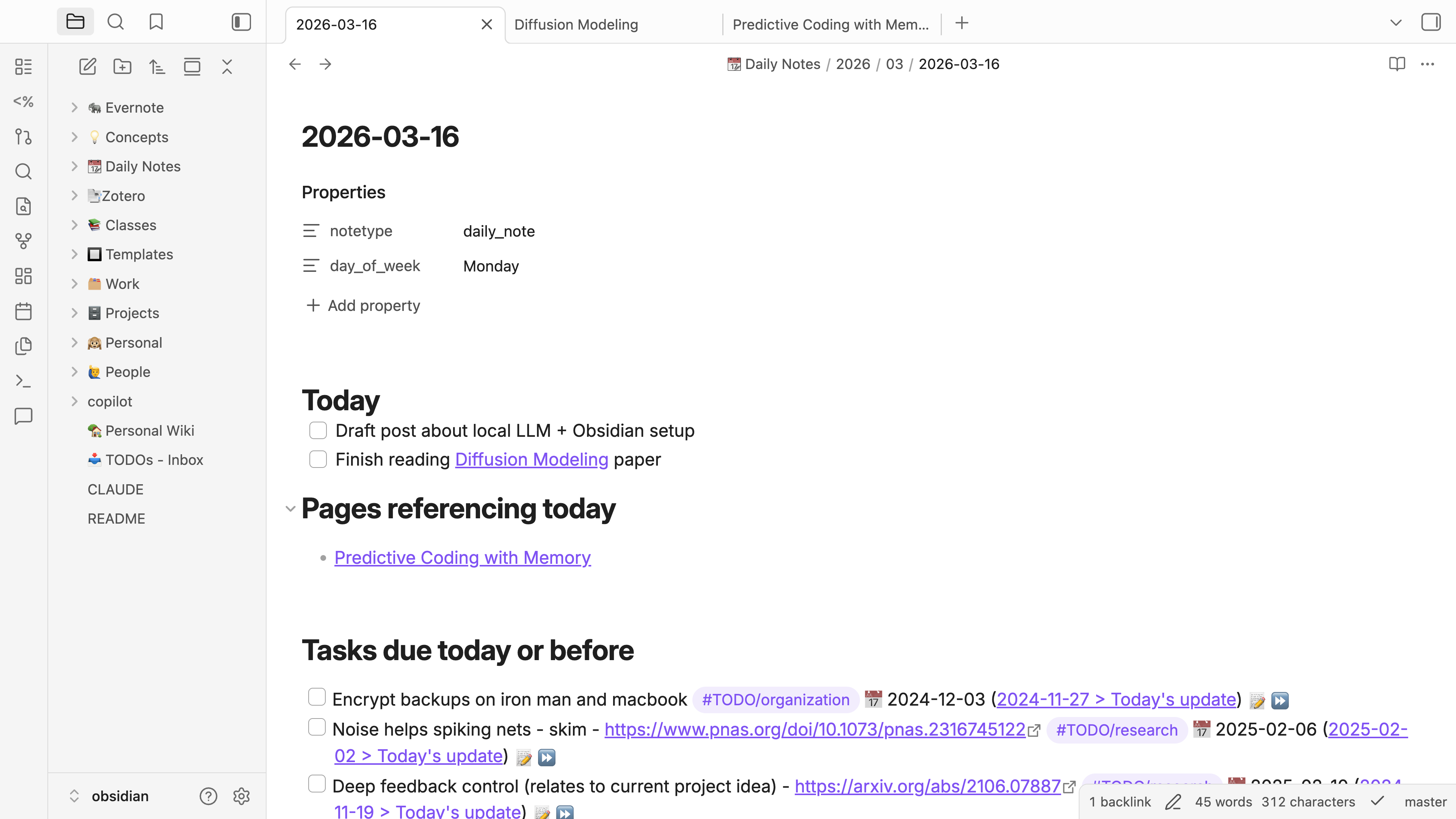
But this post is about the holy grail of self-organization and note-taking—being able to chat with your notes (i.e., your self). What I mean is that, I’d like to be able to point an LLM at 10+ years of notes and pose queries like, “summarize my honeymoon trip to Zermatt so I can provide recommendations for a friend” or “summarize my research progress over the past month”.
Let’s use a single standard query as our running example for evaluating how good a large language model (LLM) is at interacting with your Obsidian vault. I meet with my advisor weekly and I typically want to give a summary of what I accomplished over the past week. So our query will be, “What did I accomplish over the past week?”. This seems simple enough, right? But there are real challenges for an LLM to answer this question, such as getting an accurate accounting of today’s current date and finding all relevant notes, which include a combination of daily notes AND notes referencing dates from the past week.
My only hard constraint on the solution is that the model must run locally. This is because I won’t share my private Obsidian data with a vendor such as Anthropic. Everything else is a nice-to-have, such as a nice user interface, low or zero monthly subscription costs, and a fast user experience. But ultimately, I’m optimizing for whether the model can accurately answer my query.
If you’re short on time, one workable solution is:
- Host a Qwen model using Ollama on a server with a GPU.
- Run Claude Code locally on your laptop as your chat interface and point it to the Qwen model so none of your data leaves your systems.
Let’s go through the solution that I landed on and at the end I’ll compare to some other things I tried.
Solution:qwen3-coder-next + ollama + Claude Code
Let’s just go ahead and look at the output of the system based on our example query. I’m looking for a summary that pulls from ALL my notes, not just my daily notes. So summaries should draw from:
- daily notes
- project notes—for all projects (e.g., a research project) I enter a daily log of what I was working on.
- literature reviews—for many papers I read, I do a little write-up of the paper. This document is dated to the day I read the paper.
- classes—I’m both a teaching assistant (TA) for a class and auditing a class this semester, each of which have dated log entries.
Here is the lightly edited/condensed model output.
# What I Accomplished: March 9-15, 2026
## Monday, March 9-10
- Completed reading [[graves2016]]
- Finished [[behrouz2024a]] and watched a YouTube tutorial on it
- Read about memory techniques from "How to Remember Everything You Read"
- Building in time to review is probably the most important new point
- Skim a lot, read a few, re-read the best
- Don't feel obligated to finish every book - quitting books that aren't valuable is a skill
- Explored Matt Abrahams' communication strategies for giving talks
- Looked at Rich's paper recommendations for the Continual Learning & Memory Models class
## Tuesday, March 10
- Completed your Personal autocomplete LLM integrated into Obsidian setup
## Wednesday, March 11
- Had a meeting about joining a startup
## Thursday, March 12
- Met with [[Rich Zemel]] to discuss the [[Predictive Coding with Memory]] project
## Friday, March 13
- Finished grading for [[Continual Learning & Memory Models]] class
- Reviewed RL notes/assignments including Bellman optimality, Q-learning, and value iteration
- Found a diffusion modeling tutorial
- Worked on personal LLM setup for Obsidian
## Saturday, March 14 - Sunday, March 15
- Met Adrian and Emily for brunch at Lafayette
- Did some reading on [[Diffusion Modeling]]
- Continued working on personal LLM/Obsidian setup
## Key Ongoing Projects
| Project | Status |
|---------|--------|
| **Predictive Coding with Memory** | Making progress |
| **DCI Medical Project** | Discussing grant proposals |
| **Bio-learning working group** | Funding looking good, seeking collaborators |
This was largely a successful response. It followed my instructions (see below) to look at not only daily notes but ANY note containing a date from the past week. I’d say the only thing that it missed was my log entry for the Deep Learning for Robotics class that I’m auditing. Still, I’m impressed.
Chat interface
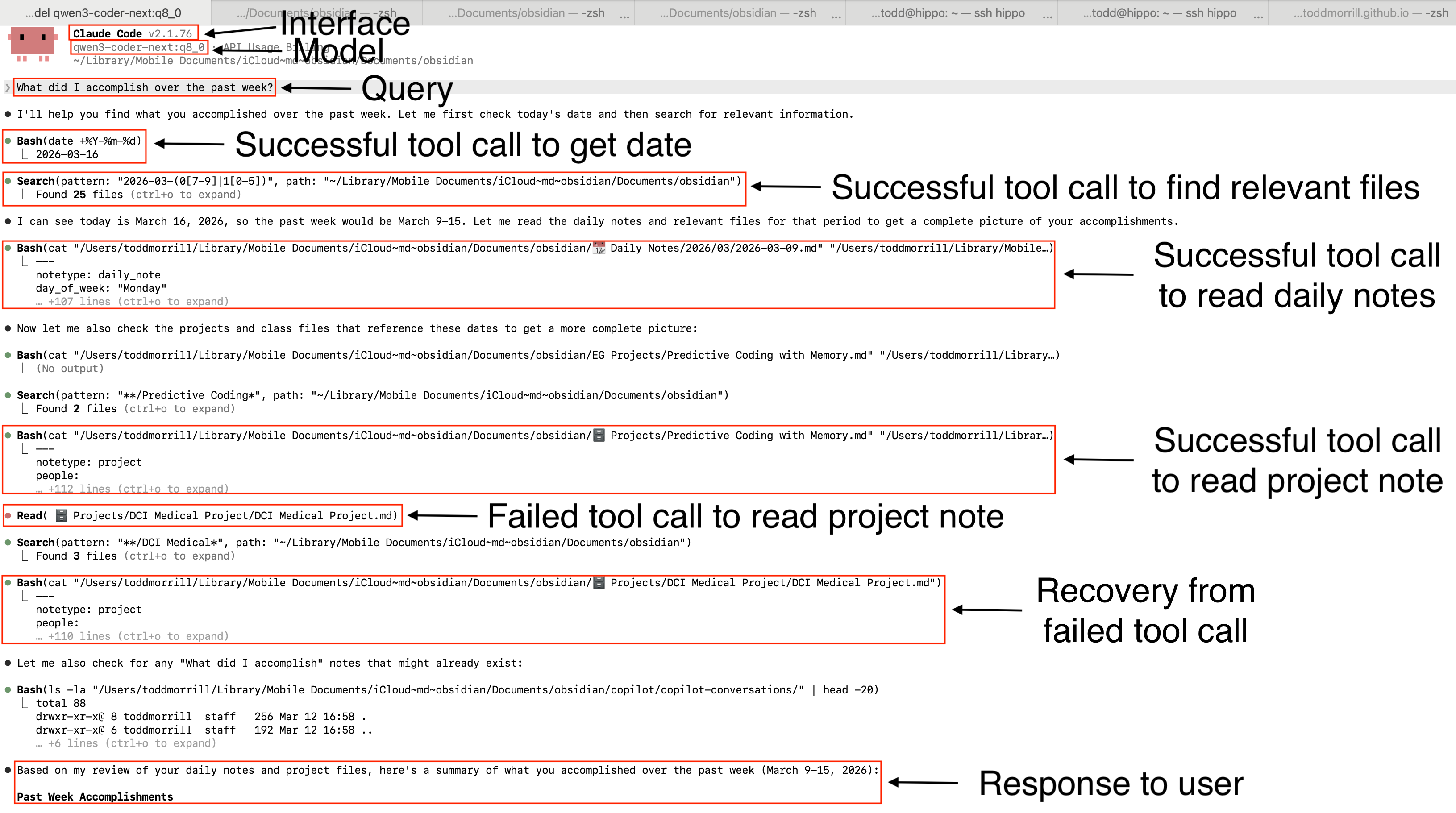
Many of you are already familiar with working with Claude Code. The benefit of using Claude Code as your interface is that you get to recycle all the engineering that went into making this your LLM’s “hands”. What I mean by that is, Claude Code already has a bunch of tools defined, like Bash, which allows a model to execute bash commands. And not only that, Claude Code is smart enough to intervene on sensitive tool calls like Bash or Write commands so that you don’t just let the LLM run wild on your laptop. You can approve each command the LLM wants to run. I’ve annotated the interaction in the Claude Code interface below.
Model Selection & Prompting
There are many considerations for which model to choose. Obviously the primary one is, can the model perform the task you’re asking it to do. Interestingly, I found the qwen3-coder-next—the qwen3-coder-next:q8_0 variant—to perform best. I think this may have to do with the fact that coding agents are heavily optimized for tool calling and interacting with the command line. I tried the rest of the Qwen3.5 models offered by ollama—qwen3.5:122b, qwen3.5:35b, qwen3.5:27b, qwen3.5:9b—and found that tool calling and/or instruction following was spotty with these models. On the small end (e.g., qwen3.5:9b), I struggled to get the model to use Claude Code’s tools. On the larger end (e.g., qwen3.5:122b), I struggled to get the model to follow my instructions to not JUST read my daily notes, but also search through the rest of my Obsidian vault for relevant files—it often only read my daily notes.
I violated my only rule—don’t let data leave my system—and tried qwen3.5:397b-cloud. This was… amazing. Not only was this 397 billion parameter good, but it was fast. You could tell a lot of solid engineering went into making the time-to-first-token snappy, and generation speeds were excellent. The downsides are that you’re sending your data to their servers, and if you’re a heavy user, you’ll eventually need to pay them for a subscription at ~$20/month. I suspect ollama has better data governance practices than Anthropic though.
Speed and hardware are other considerations. The qwen3-coder-next took 3 minutes and 15 seconds to produce the summary above. I was running on 8 A100s simply because that’s configuration of the machine I was running on, though I think you only need 80 or 90GB of GPU memory to handle this 80 billion parameter model. Some of that running time is due to ollama not storing the models in memory by default, meaning the time-to-first-token could be 30 seconds or more. Compare that with nearly instantaneous response times from a cloud hosted model.
Nothing says you have to use the models I experimented with—the world is your oyster.
Oh and by the way, I started this journey by looking at Obsidian Copilot and was really impressed. You can host your own ollama models and use their chat interface for free. Their paid tier handles these time-related queries nicely, but it involves sending your data to their server (on top of the subscription). I think my little experiment above shows that the latest open source models plus a clever CLAUDE.md are brutally effective at addressing these time-related queries.
How You Can Do This
I led with the “what”, and now I’ll give you the “how”.
Install ollama
Ideally on a server with GPUs, install ollama:
curl -fsSL https://ollama.com/install.sh | sh
If you’re on a linux machine, you’ll probably need to start the ollama server. I just started it and let it run in the background.
nohup ollama serve > ollama.log 2>&1 &
Pull down the model that you want to run with
ollama pull qwen3-coder-next:q8_0
If your model is hosted remotely (i.e., not on your laptop or local workstation), then you’ll need to do something to gain access to this model. One easy and secure option is to simply ssh into the remote server and port forward the ollama server to your local computer with
LOCAL_PORT=11435
REMOTE_HOST="hippo"
ssh -N -f -L ${LOCAL_PORT}:127.0.0.1:11434 ${REMOTE_HOST}
Install Claude Code
Install Claude Code locally (i.e., on your laptop) with:
curl -fsSL https://claude.ai/install.sh | bash
It’s essential that Claude Code is running locally, where your Obsidian vault is located, so commands like searching for files will succeed.
Define your CLAUDE.md agent instructions
I pasted my instructions below for reference. This document should live at the root of your Obsidian vault. It’s the thing I spent the most time iterating on. Take a look at the instructions below and then look at Figure 2 above to see if you notice the model actually listening to my instructions.
# Obsidian Vault Context
This directory is an Obsidian Markdown vault containing personal notes, project details, and daily logs.
## Time & Dates
- Daily notes can be found at: ``📆 Daily Notes/YYYY/MM/YYYY-MM-DD.md`` (e.g., `📆 Daily Notes/2026/03/2026-03-15.md`). Note the calendar emoji IS part of the path.
- **CRITICAL:** Before answering any question involving time (e.g., "last week", "recent", "today"), you MUST use the Bash tool to run `date +%Y-%m-%d` to establish the current timeline, as your system prompt date may be incomplete.
## Search & Extraction Strategy (The Batch-Read Rule)
You must fully read the contents of relevant files to synthesize accurate answers. Do not guess file names, and do not rely on truncated search snippets.
### Daily Note Access Rule
**STOP:** For any time-related query (e.g., "past week", "yesterday", "last month"), you MUST:
1. Use `Grep` to search for the date pattern (e.g., `2026-03-15`) across ALL files first
2. Read the non-daily-note files that reference those dates (projects, classes, papers, etc.)
3. **Only then** read the daily note files for that date range
**DO NOT** glob or read daily note files directly before completing step 1. This skips critical context from project/class/paper files that reference those dates.
### Batch-Read Workflow
1. **Find the Pointers:** Use `Grep` to find all files containing the date(s) of interest. References in class files, project files, literature reviews, etc. are top priorities. **DO NOT IGNORE FILES THAT CONTAIN A DATE OF INTEREST.**
2. **Batch Read the Files:** Once you have the list of relevant file paths, DO NOT read them one by one. You MUST use the `Bash` tool to concatenate and read all of them simultaneously in a single command (e.g., `cat "file1.md" "file2.md" "file3.md"`).
3. **Synthesize:** With the full text of all relevant files now in your context window, synthesize your final answer.
## Formatting
1. Always respond in Markdown. Never remove markdown formatting.
2. Maintain Obsidian style links (i.e., `[[filename]]`).
Put it all together
Make your life easier and just put all the setup code into a bash function that you can call every time you want to have a conversation with your vault. The following is stored in my .zshrc file on my Mac.
function qwen() {
local LOCAL_PORT=11435
local REMOTE_HOST="hippo"
local VAULT_PATH="/Users/toddmorrill/Library/Mobile Documents/iCloud~md~obsidian/Documents/obsidian"
# 1. Navigate to the Obsidian Vault safely
if [ -d "$VAULT_PATH" ]; then
cd "$VAULT_PATH" || return 1
echo "📁 Navigated to Obsidian vault."
else
echo "❌ Error: Could not find Obsidian vault at $VAULT_PATH"
return 1
fi
# 2. Check if the SSH tunnel is already active
if ! nc -z 127.0.0.1 $LOCAL_PORT > /dev/null 2>&1; then
echo "🔌 SSH tunnel not found. Connecting to $REMOTE_HOST..."
ssh -N -f -L ${LOCAL_PORT}:127.0.0.1:11434 ${REMOTE_HOST}
sleep 1
else
echo "⚡ SSH tunnel already active on port $LOCAL_PORT."
fi
# 3. Export strict environment variables for local routing and privacy
export ANTHROPIC_AUTH_TOKEN="ollama"
export ANTHROPIC_BASE_URL="http://127.0.0.1:${LOCAL_PORT}"
export CLAUDE_CODE_DISABLE_NONESSENTIAL_TRAFFIC=1
# 4. Launch Claude Code and drop into the interactive prompt
echo "🧠 Launching Claude Code with Qwen..."
# claude --model qwen3.5:35b
# claude --model qwen3.5:122b
# claude --model qwen3.5:397b-cloud
claude --model qwen3-coder-next:q8_0
}
In brief, this is going to change into your Obsidian vault’s directory, establish an SSH connection with the remotely running model, and setup Claude Code to point at the ollama model instead of their proprietary models. You can see some of the models that I was playing around with commented out. When you’re ready to have a conversation, just run
qwen
Extensions
I think there are at least two things I’d like to do extend all of this.
- I’d like to incorporate a vector database for semantic search.
- I’d like to implement some sort of a memory system that stores a summary of my conversations. Maybe this should be part of the vector search.
One idea is to use a Model Context Protocol (MCP) tool that exposes a vector store. Here’s a Python sketch from Gemini:
from mcp.server.fastmcp import FastMCP
import chromadb # Or your preferred vector DB
# Initialize the MCP Server (This is the "Frontend")
mcp = FastMCP("Obsidian Vector Search")
# Initialize your database connection (The "Backend")
db_client = chromadb.PersistentClient(path="/path/to/your/laptop/index")
collection = db_client.get_collection("obsidian_vault")
# Define the Tool using a simple decorator
@mcp.tool()
def vault_search(semantic_query: str, max_results: int = 5) -> str:
"""
Searches the Obsidian vault for relevant notes based on a semantic concept.
Always use this tool when the user asks about past events, projects, or concepts.
Args:
semantic_query: The core concept to search for (e.g., "machine learning papers", "skiing").
max_results: The maximum number of notes to return.
"""
# Execute the actual vector search
results = collection.query(
query_texts=[semantic_query],
n_results=max_results
)
# Format the results into a string to return to the LLM
formatted_output = "Found the following notes:\n\n"
for i, doc in enumerate(results['documents'][0]):
# Injecting native Obsidian links
formatted_output += f"Source: [[{results['metadatas'][0][i]['filename']}]]\n"
formatted_output += f"Content: {doc}\n\n---\n"
return formatted_output
# Run the server via stdio
if __name__ == "__main__":
mcp.run(transport="stdio")
You can simply tell Claude Code about the existence of this tool with something like
claude mcp add obsidian-search -- python ~/scripts/vault_search.py
and it will be able to send queries to your vector search engine. I just need to do a little more work to figure out how to break down documents and index them. I’d likely add another function in vault_search.py that’s responsible for updating the index, so that I can update the index daily.
Another thing I’d like to do is store a memory of past conversations, mostly because it may add a degree of personalization.
Conclusions
This has been fun. It got me caught up on the buzz around agents, allowed me to understand the key leverage points (e.g., CLAUDE.md, MCP tools, etc.) for controlling the system, and allowed me to kick the tires on open source model capabilities. I’m starting to see a future where private, personalized, and capable AI gets embedded into my workflow.


Leave a comment