
Association for Computational Linguistics (ACL) Conference
TLDR; I recently attended the ACL conference, where I learned about dialog systems and NLP for robotics.
This past week I attended the conference for the Association for Computational Linguistics (ACL). It is one of the premier venues for NLP research and naturally all of the big names were in attendance (e.g. Google, Facebook, etc.). This was my first time attending so I can’t speak about previous years but it was interesting to see such a strong presence from the Chinese tech firms (e.g. Baidu, Tencent, Alibaba, etc.) not to mention the representation from the Chinese research arms of the US tech firms (e.g. Microsoft Beijing, etc.). China has a deep pool of technical talent and they’ve made their goals clear, not mention comments like these from Andrew Ng, “China is very good at inventing and quickly shipping AI products.”
Beyond that, it was my first truly academic conference and it was exciting to learn more about how the community works (e.g. double blind reviewing, presentations of very incremental developments, etc.). I’d like to highlight a few of my key learnings below.
For context, my team has done a lot of work with vector representations but we still have much to learn. In the neural realm, we’ve worked with word2vec/GloVE embeddings, LSTMs for classification tasks, autoencoding using seq2seq architectures, information retrieval chatbots, text summarization, and unsupervised clustering of word/document representations. With that in mind, we haven’t done a tremendous amount with knowledge bases, slot filling in dialogue systems, or grounding language to actions for robotics. I’m sure others in attendance got a lot from the very technical updates on new attention mechanisms or updated gating structures in RNN cells, but I was learning about broader brushstrokes.
Paper Review
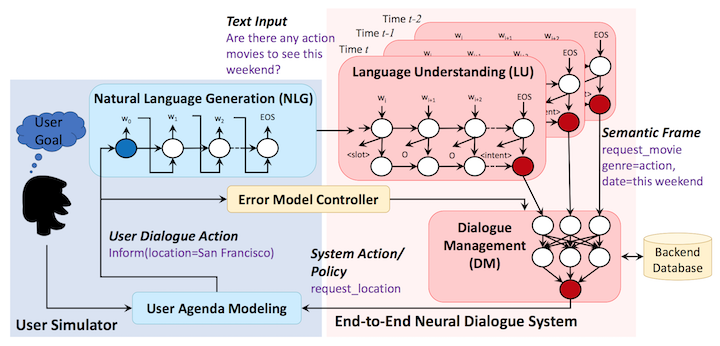
One paper that was fairly eye opening was End-to-End Task-Completion Neural Dialogue Systems. I attended Vivian Chen’s workshop on dialogue systems on Sunday before the conference started. The paper describes an end-to-end goal-oriented chatbot that helps a user book movie tickets. The idea is that the user can ask questions and naturally specify what they’re looking for (e.g. What time is the new Star Wars movie playing at Cinemax?). The authors’ approach uses a combination of Supervised + Reinforcement Learning.

The first module is a language understanding (LU) model, an LSTM, that both predicts intent (e.g. greeting, request info, inform the bot, etc.) and slots (e.g. place, time, movie, number of tickets, etc.), which are used to query the relevant database (e.g. a database of movie info). The training for the LU is done in a supervised fashion, relying on prelabeled sequences. In other words, the LSTM learns the mapping from the text sequence to the intention and slots.
The LU module outputs intent and slots (i.e. symbolic representations) that are then passed to the dialogue management (DM) module. The DM module is responsible for querying the database using the intent and slot information, summarizing the current state (i.e. all previous user utterances, previous bot utterances, etc.), and learning a policy that takes actions based on that state (e.g. ask the user for more info). The DM module is warm-started in a supervised fashion and continues learning the policy to take actions using reinforecement learning.
They employ a user simulator, which is a proxy for a true user and is a way to augment the training data. The simulated user uses a natural language generation (NLG) module, which is a sequence-to-sequence module that takes requests/actions as input and outputs a sketch sentence. They employ some heuristics to clean this output sentence up. Again, existing training data is used to train this sequence-to-sequence model in a supervised fashion. To be sure, the output of the user simulator is what is sent to the LU module described above.
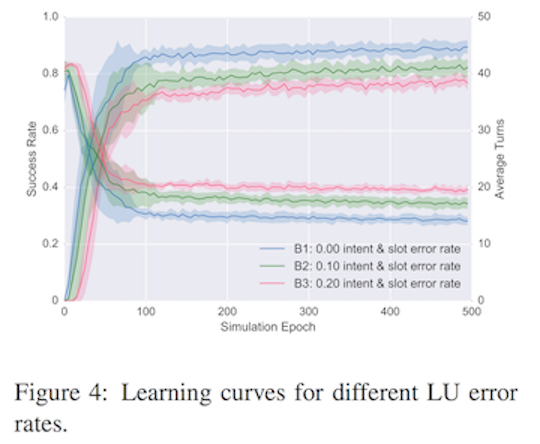
The authors also add in intent and slot level noise to the text sequences to test how robust the model is noisy input (i.e. the real world). Naturally, as you increase the noise, the performance of the system is likely to degrade, which is largely what we observe in the success rate of the conversation. The conversation outcome is binary and is marked as a success if (1) a movie is booked, and (2) the movie satisfies the users constraints.
Beyond this paper, it will be interesting to see how RL plays a role in future learning systems, especially in situations where there is not necessarily labeled training data or where the system needs is allowed to continue improving through interactions with the real world.


Leave a comment